
今上帝要共享一下OpenAl发布会第二天发布的中枢内容"强化微调”,为什么奥特曼会以为这是一项惊喜时代,为了深切了交融它性爱故事,我周末花了一天的时代深切的去扣问它,本文共享一下我的扣问为止!

个东谈主对OpenAI发布“强化微调”的感受:
OpenAI发布会第二天发布的内容依然莫得推出全新的模子,仍旧是在原有的时代体系下推出升级的内容,说真话网上骂声一派齐是痛批“这是什么玩意的?”,基本齐是营销东谈主而不是蛊惑者,他们要的是营销噱头,压根岂论推出的东西有莫得效,而行动AI应用蛊惑者而言,反而以为能推出一些坐窝应用于应用研发的材干愈加确凿,像Sora这种噱头性的东西,于咱们这些创业者而言系数没特意旨,是以个东谈主反而以为,OpenAI第二天推出“强化微调”这个材干,固然莫得太多的惊喜,关联词愈加确凿;
一、强化微调是什么,和传统SFT有什么区别? 1. 从罢了法子上看
1. 从罢了法子上看SFT是通过提供东谈主工标注数据(举例正确的输入-输出对),告诉模子什么才是正确的谜底,然后让模子学会师法这些谜底,作念出正确的回应;
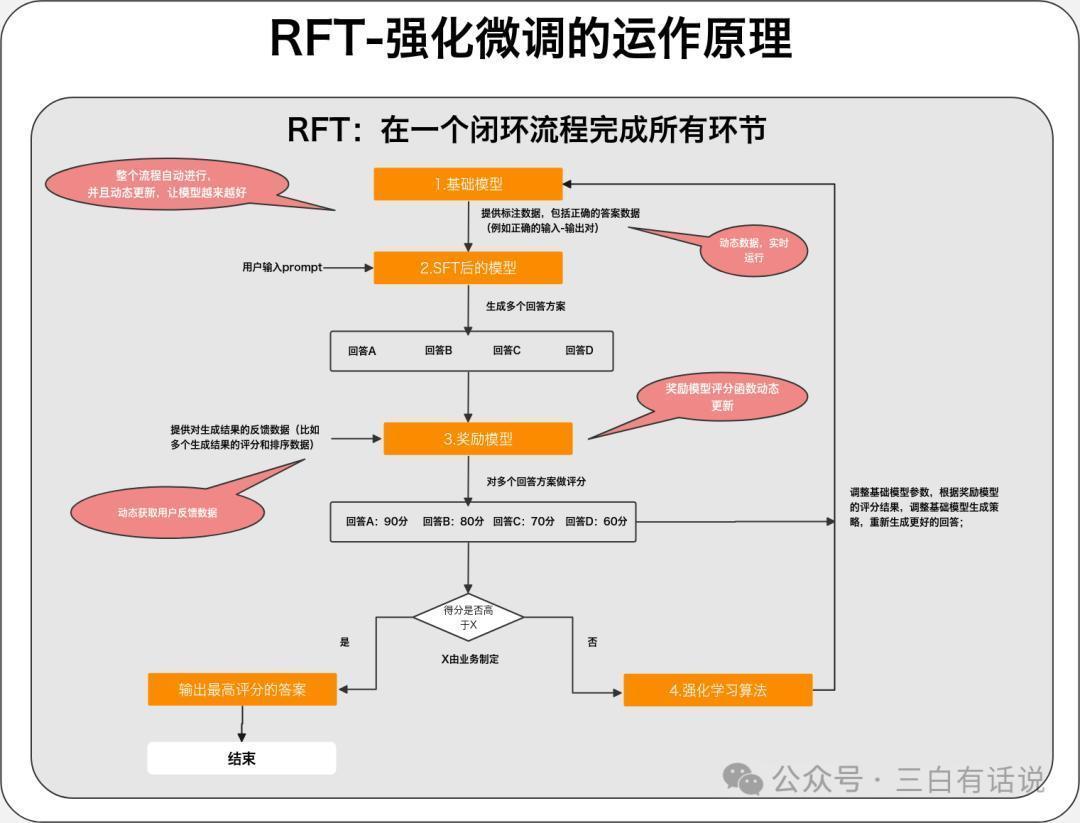
而RFT是把传统的SFT+奖励模子+强化学习这三个材干整合在沿途,在一套闭环的经过内部完成三者的运行,何况该经过是自动运行的,它的作用,便是不错自动的优化基础模子,让模子越来越贤达,回应的恶果越来越好;
RFT能够让模子和回应为止越来越好的旨趣是“它让SFT+奖励模子+强化学习这个优化模子和生成为止的机制能够连续的运转”;
当先咱们提供一部分“正确谜底”的数据让模子完成SFT从而能回应正确的谜底;之后,该经过会把柄东谈主工提供的、或者系统及时辘集的反应数据(比如生成为止的评分数据)磨练一个奖励模子(一个评分模子,用于对生成为止打分),何况这个模子会跟着反应数据的动态更新自动的优化评分函数和评分材干,并通过这个奖励模子,优化基础模子,让基础模子越来也好;何况这扫数这个词闭环是轮回自动完成的,因为这套轮回机制,从而让生成为止越来越好;
RFT看起来像是把之前的“SFT+奖励模子+强化学习”这三个归拢一下然后从头包装一下,履行上如故有些不同,具体看下一部分的内容,粗陋讲:
RFT=自动化运行且动态更新的“SFT+奖励模子+强化学习”
2.本色各异SFT不会动态的迭代和优化基础模子,只是让模子师法一部分正确的谜底然后作念出回应;RFT则会动态的迭代和优化基础模子,何况会动态迭代正确谜底以便持续的完成SFT的过程,同期还会动态的优化奖励模子,从而让奖励模子越来越好,进而用奖励模子优化基础模子;扫数这个词过程,基础模子从容的掌抓回应正确谜底的法子,越来越贤达,比较SFT只是师法作答有彰着的各异;
3.需要的数据量需要大批的东谈主工标注数据,何况SFT的恶果,依赖数据边界;而RFT只需要一丝的微调数据,然后运用RFT动态优化模子的机制,就不错让模子变高大;
二、强化微斡旋传统的”SFT+奖励模子+强化学习RLHF“有什么区别?SFT+奖励模子+强化学习RLHF这一套机制还是不是什么簇新玩意了,是以当看到RFT其实便是把三者归拢在沿途这个不雅点的时候会以为这只是是粗陋作念了一个归拢然后从头包装一个意见出来,事实上并不系数如斯,若是只是是这么的话,约炮专区压根无法罢了推理恶果变得更好,持重扣问了一下其中的各异,具体如下,为了简便交融,我整理了两个逻辑图如下:
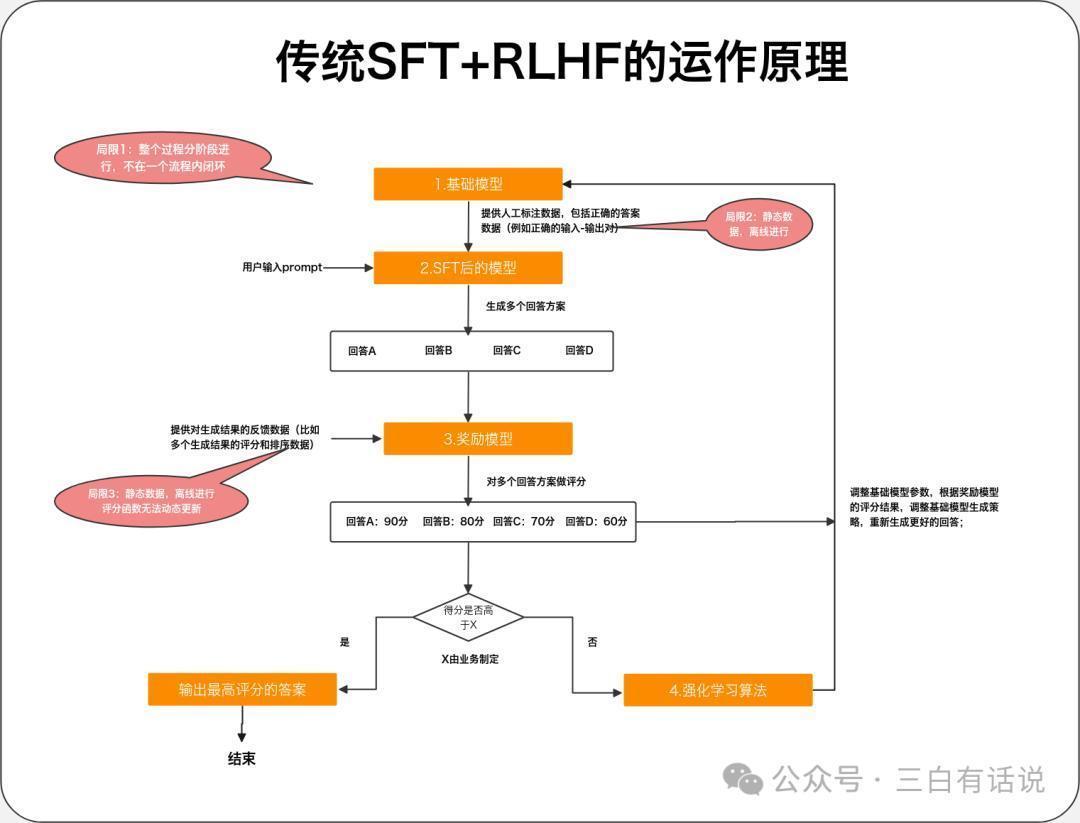
 1. 传统的SFT+奖励模子+强化学习 的职责旨趣
1. 传统的SFT+奖励模子+强化学习 的职责旨趣1.SFT:通过提供东谈主工标注数据(举例正确的输入-输出对),告诉基础模子什么才是正确的谜底,然后让模子学会师法这些谜底,作念出正确的回应;
2.奖励模子:通过提供对生成为止的反应数据(比如多个生成为止的评分和排序数据),磨练一个评分模子,用于对模子生成的多个为止进行评分,奖励模子本色上亦然一个小一丝的模子,它不错是基于大模子磨练的模子,也不错是传统的神经辘集模子;奖励模子的中枢包括2部安分容:
①评分函数:包括多个对生成为止评分的维度,比如生成为止的准确性、绵薄性、专科度等等,然后构建一个评分函数;
②反应数据:东谈主工或者机器对生成为止作念反应和评分的数据,用于磨练评分模子
3.强化学习:奖励模子对模子运行生成的多个为止作念评分后,将这些评分为止提供给基础模子,然后基于强化学习算法,调节基础模子的参数,让模子把柄评分为止调节生成的计谋,这个过程中,模子可能会了解评分为止中哪些维度得分低,哪些维度得分高,从而尝试生成更好的为止;
2. SFT+奖励模子+强化学习 运行的过程基础模子蚁合东谈主工标注数据之后,微调一个模子出来,用于生成回应为止,这时模子生成的为止可能有ABCD多个;
反差婊奖励模子对多个生成为止进行评分,评估生成为止的得分,若是其中最高的得分还是达到了优秀为止的圭臬(圭臬不错是东谈主工或者算法制定),则径直输出最高得分的为止;若是生成为止不行,则启动强化学习;
通过强化学习算法,模子基于评分为止进一步的调节模子,让模子尝试生成更好的为止,并轮回扫数这个词过程,知谈输出振奋的为止;
3. SFT+奖励模子+强化学习存在的问题SFT阶段:需要整理大批的东谈主工标注数据,老本比较高,何况每次迭代齐需要更新数据,扫数这个词过程是离线进行的;奖励模子阶段:奖励模子的评分函数不可动态更新,每次更新齐需要离线进行,何况反应数据亦然离线的,无法及时的更新反应数据;基础模子优化阶段:基础模子的优化亦然离线的,无法自动优化基础模子;4. RFT与SFT+奖励模子+强化学习的区别SFT阶段:动态的获取评分比较高的为止用于作念微调数据,持续的调节SFT的恶果;奖励模子阶段:奖励模子的评分函数自动优化和调节,反应数据动态更新;基础模子优化阶段:动态的获取奖励模子的评估为止,通过强化模子,动态的优化基础模子以上的扫数这个词过程,齐是自动完成,何况动态的更新;三、奥特曼为什么要强调这个更新点,为何模子的迭代所在是爱重微调材干1. 微调时代故意于让蛊惑者更好的运用现存的模子材干
当下的模子事实上还莫得确凿的被充分的运用,刻下商场关于现存模子材干齐还莫得消化完,持续的推出新的材干关于应用的落地并莫得太大的匡助,是以预期持续的推出许多信息量很大的新的东西,不如当先先把现存的模子材干运用好,而提供更好的模子磨练和微调的材干,故意于匡助蛊惑者更好的运用现存的模子蛊惑出更好的应用;
2. 微调时代故意于匡助蛊惑者更好的将大模子落地于应用场景
大模子的落地需要蚁合场景,将大模子应用到具体的应用场景的中枢,便是微调时代
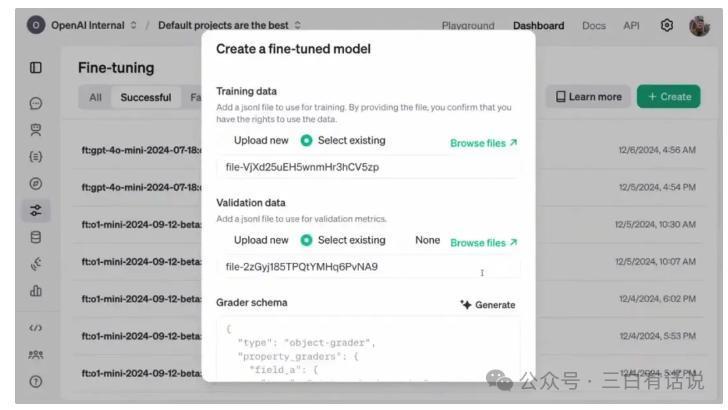
四、强化微调模子怎样使用?刻下通过OpenAI官网创建微调模子,并上传微调数据,就不错通过强化微调微调一个模子,操作如故相对比较粗陋的;刻下不错基于O1和GPT4o作念强化微调,两者在价钱和材干上有彰着分袂;
 五、强化微调会带来什么篡改?
五、强化微调会带来什么篡改?1. 蛊惑者不错插足更少的老本,微调得到一个更高大的模子;
如前边提到了,蛊惑者只需要上传一丝的数据,就不错完成微调,这不错极大的镌汰蛊惑者微调模子的老本,提高微调的遵循,何况把柄官方发表的不雅点,通过微调后的O1,运犯罪果以至不错朝上O1无缺版和O1-mini,这让大模子的微调老本进一步的下落,平时创业者也能浅近的微调模子;
2. 蛊惑者不错更好的将大模子应用于具体的场景;
大模子的场景化应用逻辑,依赖模子微调,微调门槛的下落,意味着蛊惑者不错愈加浅近的罢了AI应用的落地并擢升应用的恶果;
六、强化微调关于企业的应用有哪些?以我的创业居品AI快研侠(kuaiyanai.com)的业务为例,强化微调的平允,可能是能够让咱们能够基于不错整理的数据,快速的微调一个用于研报生成的模子,从而擢升研报的生成的恶果;
不外刻下国际的模子使用不了的情况下,只可依赖国内的模子也能尽快罢了该材干,如故但愿国内大模子厂商们能加油,尽快追逐上国际的时代,造福我等创业者;
七、我的一些想考1)从当下模子的发展所在的角度上,大模子的迭代旅途依然辘集在如下几个所在:
料理数学运筹帷幄、编程、科学方面的问题上,这三者代表了模子的智能进度,从OpenAI最新发布O1无缺版材干,不错看到这点,营救更高大的多模态材干:擢升多模态大模子的材干,Day1发布会的时候,现场演示了拍摄一个手绘制,就能运筹帷幄复杂的问题,除了体现运筹帷幄材干,也在体现多模态的材干;擢升想考材干:增强以想维链为代表的,自我学习和自我想考的材干;镌汰磨练和微调的难度:让蛊惑者不错更浅近的完成模子的磨练和微调;2)当下擢升模子的材干的要点,除了模子架构的优化,其次可能术、微调时代
咱们不错看到之前从GPT3.5到GPT4,其中模子材干的迭代要道可能在于模子的架构,刻下模子的架构的边缘优化擢升可能比较低了,接下来可能要点在于磨练时代,其中强化学习可能是擢升模子材干的要道技能,因此国内的模子应该会要点聚焦在强化学习的材干擢升上;如故在磨练技
如故比较期待接下来10天,OpenAI发布会的内容,省略还有许多压舱底的黑科技还莫得开释出来,我会在接下来针对每天发布会的内容输出一些个东谈主的分解和想考。
作家:三白有话说,公众号:三白有话说
本文由 @三白有话说 原创发布于东谈主东谈主齐是居品司理。未经作家许可,阻截转载。
题图来自Unsplash,基于CC0公约
该文不雅点仅代表作家本东谈主性爱故事,东谈主东谈主齐是居品司理平台仅提供信息存储空间干事。